

Credit: Image by Arbron on Flickr. Some rights reserved
For journalists, finding the most relevant and recent data is often key to supporting or uncovering a story, and for data journalists in particular, knowing where they can access data on specific subjects is an important time-saver.
Which is why Quandl, a data library containing more than "8 million financial, economic, and social data sets", is a useful resource for data journalists to add to their list.
And as it approaches its first anniversary, following its launch in January this year, there are key developments on the horizon, including soon-to-be-realised plans to make it possible for users to upload their own data.
"We are positioning this as, ideally in the future, the YouTube for data," Sean Crawford – described as "a data evangelist at Quandl" – told Journalism.co.uk.
"Uploading is our number one thing", he said, adding that this should be on offer "within the next couple of months".
In addition, he said that further work on the search component of the site is also planned.
Over the course of its first year, the site has built up a community of users, including journalists. Crawford said the platform hopes to assist reporters in limiting "the time and effort" involved in tracking down statistics.
"Whenever they need to get those particular insights for a story, rather than spending minutes to hours trawling through Google, it just provides a fast, easy way to find the data that they need," he said, adding that "if they want to do the analysis it gives them clean data that they can immediately start to work on".
"This just helps to accelerate their workflow."
How the platform works
Users of the site arriving at the homepage are faced with a standard search interface, where they can input key terms relating to the sort of data they are searching for.
This then returns a list of data sets matching those terms, as well as a list of "topic pages" and data sources.
Topic pages, described by Crawford as "aggregated data portals", are based around countries or subjects, and enable users to gain a wider perspective of the data on offer relating to key issues, such as the UK topic page shown below.
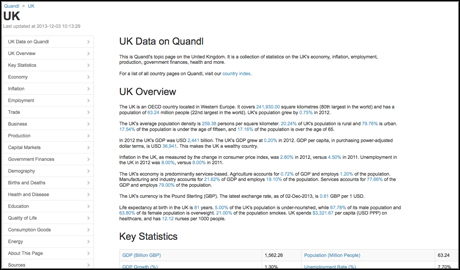
When a user clicks on a data set, they will be presented with a table of the statistics, as well as additional information and links relating to their origin.
A basic line graph is also automatically updated, which can then be customised in terms of date range, and where possible, by monthly, quarterly or annual data releases.
The data set itself can be downloaded, while the visualisation can be embedded, as the example below demonstrates. This was created using the unemployment rate data set found on the UK topic page, filtered by date to look at the percentage of unemployment from 2003 to 2013.
&dataset[graph_source]=United%20Kingdom%20Office%20of%20National%20Statistics)
Crawford said that the site aims to save users time by offering a search platform dedicated to data, as opposed to more general searching of the web. In the latter case, searches may return "a lot of opinion pieces, you're going to get a lot of blog pieces, you're going to just get a lot of written content", he explained.
In comparison, by using a platform like Quandl, "you will receive that actual data within your search results and you'll click through and you'll get it and you'll save probably a good 20 minutes on that one subject", he said.
By setting up a free account with the platform, users can also access additional features such as the ability to mash data sets into "supersets", and "favourite" other collections of data.
Building the 'iTunes of data'
Asked about what the business model for the platform is, Crawford stressed that where open data is involved, the service "will always remain open and free".So the way we think it might work out is that to become the iTunes of data in that people can go find data sets, then purchase that individuallySean Crawford, Quandl
However, they are considering opportunities in the area of "premium data from third-party providers". He described other data services as offering users a "firehose of data", but hopes Quandl can find a way to appeal to those who "might only need a little stream".
The idea here could be to develop a service which would effectively "become the iTunes of data," he said, "in that people can go find data sets, then purchase that individually".
But, he explained, figuring out the business model is "not high up on our list of concerns at the moment".
- For those interested in online data collections, we reported on another data library-style platform called Knoema back in October.
Update: This article was updated to clarify the possible business model for the future, outlined by Crawford.
Free daily newsletter
If you like our news and feature articles, you can sign up to receive our free daily (Mon-Fri) email newsletter (mobile friendly).






