

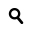

Credit: Image by Arbron on Flickr. Some rights reserved
A tool which helps non-coding journalists scrape data from websites has launched in public beta today.
Import.io lets you extract data from any website into a spreadsheet simply by mousing over a few rows of information.
Until now import.io, which we reported on back in April, has been available in private developer preview and has been Windows only. It is now also available for Mac and is open to all.
Although import.io plans to charge for some services at a later date, there will always be a free option.
The London-based start-up is trying to solve the problem of the fact that there is "lots of data on the web, but it's difficult to get at", Andrew Fogg, founder of import.io, said in a webinar last week.
Those with the know-how can write a scraper or use an API to get at data, Fogg said. "But imagine if you could turn any website into a spreadsheet or API."
Uses for journalists
Journalists can find stories in data. For example, if I wanted to do a story on the type of journalism jobs being advertised and the salaries offered, I could research this by looking at various websites which advertise journalism jobs.
If I were to gather the data from four different jobs boards and enter the information manually into a spreadsheet it would take would take hours if not days; if I were to write a screen scraper for each of the sites it would require knowledge and would probably take a couple of hours. Using import.io I can create a single dataset from multiple sources in a few minutes.
I can then search and sort the dataset and find out different facts, such as how many unpaid internships are advertised, or how many editors are currently being sought.
How it works
When you download the import.io application you see a web browser. This browser allows you to enter a URL for any site you want to scrape data from.
To take the example of the jobs board, this is structured data, with the job role, description and salaries displayed.
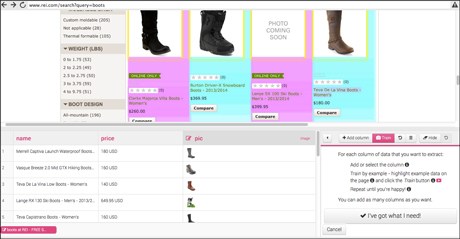
The first step is to set up 'connectors' and to do this you need to teach the system where the data is on the page. This is done by hitting a 'record' button on the right of the browser window and mousing over a few examples, in this case advertised jobs. You then click 'train rows'.
Building an extractor in import.io
It takes between two and five examples to teach import.io where all of the rows are, Fogg explained in the webinar.
The next step is to declare the type of data and add column names. For example there may be columns for 'job title', 'job description' and 'salary'. Data is then extracted into the table below the browser window.
Data from different websites can then be "mixed" into a single searchable database.
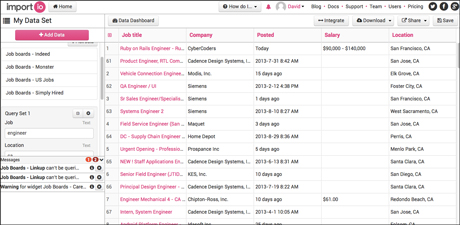
The dataset page
In the example used in the webinar, Fogg demonstrated how import.io could take data relating to rucksacks for sale on a shopping website. The tool can learn the "extraction pattern", Fogg explained, and apply that to to another product. So rather than mousing over the different rows of sleeping bags advertised, for example, import.io was automatically able to detect where the price and product details were on the page as it had learnt the structure from how the rucksacks were organised. The really smart bit is that the data from all products can then be automatically scraped and pulled into the spreadsheet. You can then search 'shoes' and find the data has already been pulled into your database.
When a site changes its code a screen scraper would become ineffective. Import.io has a "resilience to change", Fogg said. It runs tests twice a day and users get notified of any changes and can retrain a connector.
It is worth noting that a site that has been scraped will be able to detect that import.io has extracted the data as it will appear in the source site's web logs.
Case studies
A few organisations have already used import.io for data extraction. Fogg outlined three.
- British Red Cross
By using import.io, data was scraped from the NHS site. The app is now in the iTunes store and users can use it to enter a postcode to find hospital information based on the data from the NHS site.
"It allowed them to build an API for a website where there wasn't one," Fogg said.
- Hewlett Packard
They used import.io to scrape the data from the various sites and were able monitor the prices at which the laptops were being sold in real-time.
- Recruitment site
Free daily newsletter
If you like our news and feature articles, you can sign up to receive our free daily (Mon-Fri) email newsletter (mobile friendly).
Related articles
- Can AI help overcome biases and shortcomings in data journalism?
- 16 free sources of data on the media industry
- Six tools to elevate your data storytelling
- Nine AI hacks for newsroom leaders to promote employee wellbeing
- Tool for journalists: Baekdal News Analyzer, for making news content more relevant







